
This is some notes for Meta Analysis
Part of this page is a note of the video: https://www.bilibili.com/video/BV1QW411S7S2
选题和检索
选题
- 选题的重要性:
今天选题的高度界定了你日后发文的高度。
开始已注定结局之归属。
磨刀不误砍柴工,好好选题,良好的开端是成功的一半。
- 优质题目的特征
是临床现有的争议点,大家对此还不是很统一,指南也模棱两可
对现有操作的一种challenge
如果之前已经有一篇meta了,但后来因为加入新的articles,挑战了之前的结果,能引起一定的讨论
- 技巧与原则 (如何能想出好的题目)
看本专业Top临床期刊最新的articles和review
看指南的治疗部份
去逛逛临床试验的注册网站
中医方面的meta
检索策略
外文:pubmed, google scholar, Cochrance clinical trail
中文:万方 CNKI
检索词: xx药治疗xx病
主题词(MeSH) + 自由词
控制在1000-2000篇
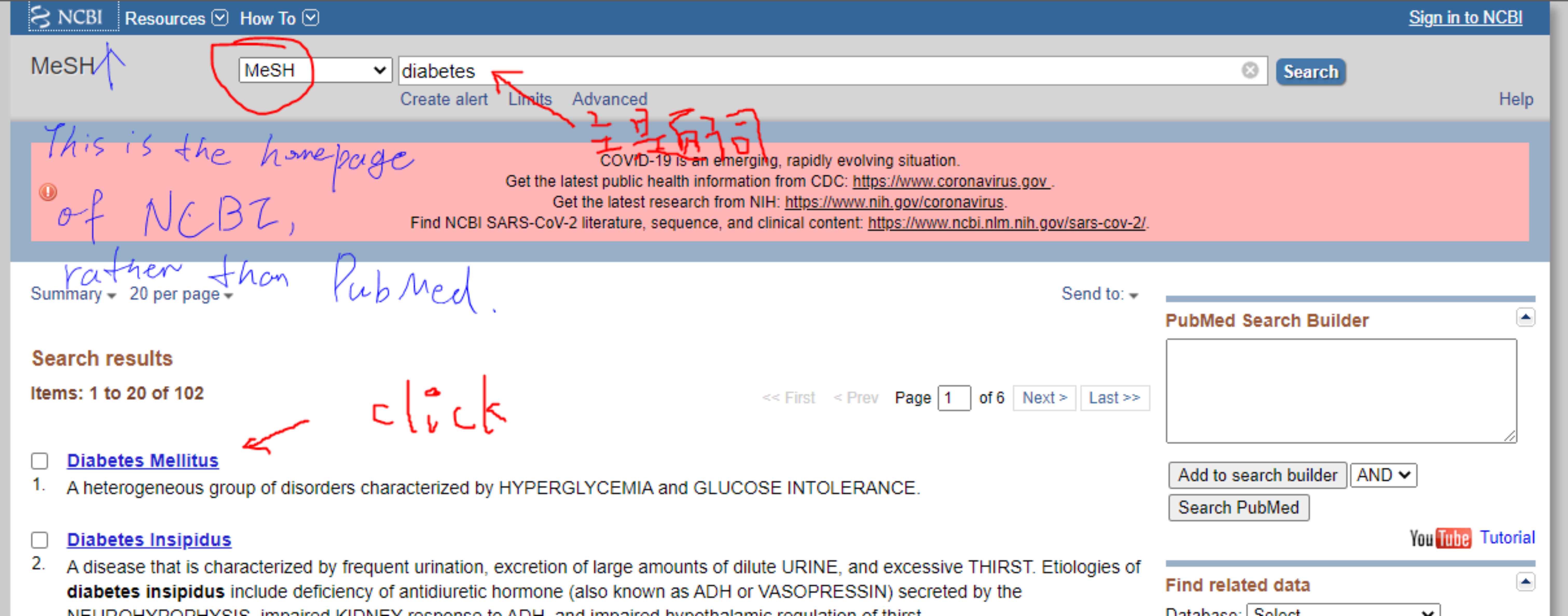
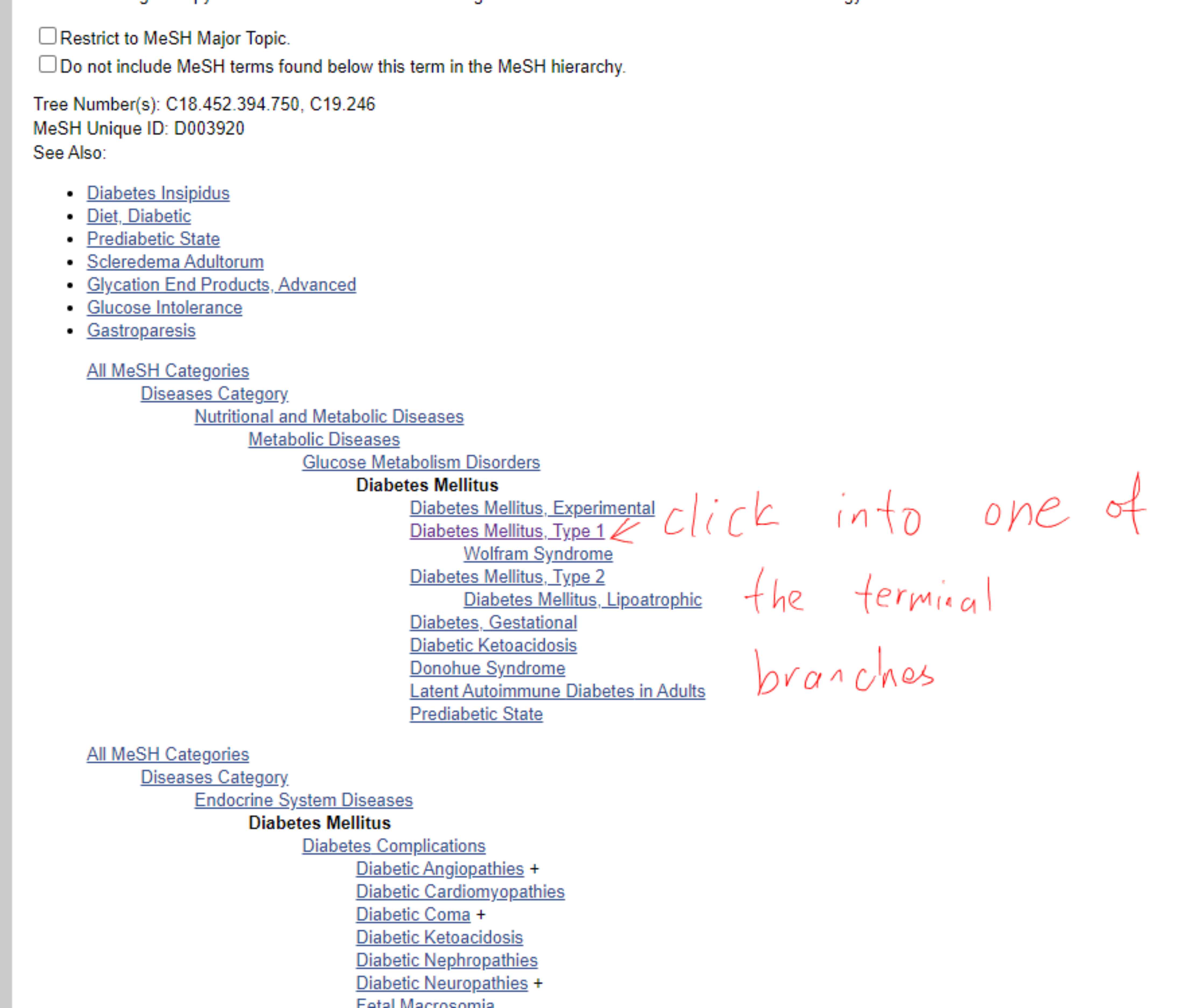

一般情况下,我们的问题方向都有好几个主题词,我们这样检索:
(主题词1(mh)) OR 自由词1_1 OR 自由词1_2 …
AND
(主题词2(mh)) OR 自由词2_1 OR 自由词2_2 …
AND
…
特征表和质量评价
特征表
对下载的文章进行特征上的总结,让阅读者无需阅读文章就能了解所有我们需要从这个文章中获取的信息。
特征表一定要详细、充实,同时保持美观大方
阅读几篇文章后先对自己想要知道的信息进行排版(同时看几篇相关的meta分析文章,看看别人是怎么做的)
千万不要自己瞎想乱画
对自己的delivery要挑剔,不要自己都看着不顺眼还拿给别人看
熟练掌握工具
- 一篇文章中我们要提取的内容(以RCT为例):
作者姓名
发表时间
实验组和对照组的纳入规范
随访时间多长
干预手段是什么
结局指标都有哪些
…
它是没有固定框架的,提前根据自己阅读文献积攒下来
质量评价表
用来评价纳入文献的质量
流行的三种质量评价量表:cochrane手册 jadad量表 delphi共识
Cochrane 评价条目:
评价结果:YES, NO, UNCLEAR
Sequence generation (序列产生):使用随机数字表、计算机随机、抛硬币、洗扑克或者信封、抽签、掷骰子时给1分
Allocation concealment (分配隐藏):中心化分配、统一外观、连续编号的药物容器、不透明的信封给药
Blinding (盲法):有采用盲法的给1分
Incomplete outcome data (不完全结局资料):没有丢失结局的数据,采用意向性分析(ITT, Intention to Treat)给1分
No selective outcome reporting (选择性结局报告):无选择性结局报告给1分
Other sources of bias (其他偏倚来源):研究表现出没有其他偏倚来源的、给1分
数据分析与发表偏倚
数据分析的目的:使用多方结果,通过数据合并,达到了扩大样本量的效果。结果可用于指导临床。
- 数据类型:
二分类变量
连续型变量
所谓荟萃分析,其所使用的数据不过是每个研究的统计量(RR OR RD SRD WRD 等)以及这个统计量的标准误(SE),由于写教程的人貌似都不是很懂统计,总是把这个标准误叫做方差。
</strong>
meta分析主要使用森林图,文章中有几个结局指标,就有几个森林图。
森林图看以下几个方面:
- 异质性检验
- p value
- 效应尺度 (Difference)在连续型变量中,mean difference 分为 weighted mean difference 和 standard mean difference 其中WMD在当对同一干预措施的测量方法或单位相同时使用;SMD在不同的测量方法或测量不同的单位时使用
- 效应模型 (分为随机效应模型和固定效应模型)
异质性检验
公式:
</strong>
其中W是每一个研究统计量的权重,d是每一个研究统计量的标准误
Q是一个服从自由度为K-1卡方分布的统计量 (K是研究统计量的个数)
I2是一个与Q相关的统计量
I2 > 50% 为异质性 使用随机效应模型
I2 < 50% 为同质性 使用固定效应模型
发表偏倚
在同类研究中,有统计学意义的研究结果比无统计学意义的结果更容易发表,可以会产生错误的结论
发表偏倚的检验方法:
漏斗图:样本量越大越集中在上方;样本量越小越集中在下方。若两边对称则无明显发表偏倚,两边不对称则可能存在发表偏倚
Egger test // Begg test:给出了统计描述。其中p>0.05提示无明显发表偏倚,p<0.05存在发表偏倚
当三者结果不一致时,Egger test > Begg test > Funnel plot
检测发表偏倚也是需要文献达到一定数量的 (7 - 10篇以上)
敏感性分析和亚组分析
当有异质性怎么办?
强迫症就此放弃这个meta分析
分析异质性的来源
2.1. 敏感性分析
改变分析模型 (随机或固定效应模型)
逐篇排除文献(逐个找,找到后评价为什么它是异质性的来源)
剪补法(减去漏斗图中不对称的小样本研究,用修剪后的对称部分估计漏斗图的中心值,然后沿中心两侧添补被剪切的以及相应的估计缺失研究)
当敏感性分析前后结果一致,说明结果较为稳健
当敏感性分析前后结果不一致,说明结果不稳健,需谨慎对待
2.2. 亚组分析
分性别组、年龄组、药物浓度、治疗时间长短等等
比如按研究类型分两压阻,两组内都同质,合并后就成了异质,说明研究类型可能是异质性的来源
合并统计量
我们要把多个独立研究的多对儿统计量合和标准误成一个统计量和标准误。合成出来的统计量叫效应量,合成的标准误是效应尺度。
</strong>
合并统计量的两种模型:
固定效应模型: Fixed Effect model
随机效应模型: Random Effect Model

















